冬天好冷,加上mac的金属外壳,更冷。写个暖宝宝给MAC吧,好歹手会不会再冷了。
import multiprocessing |
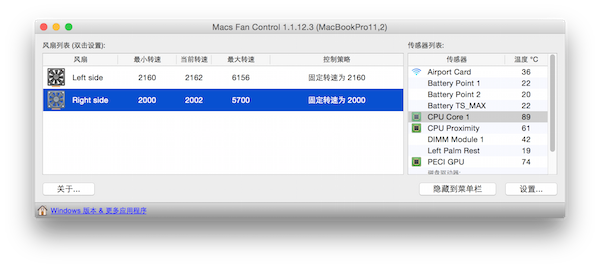
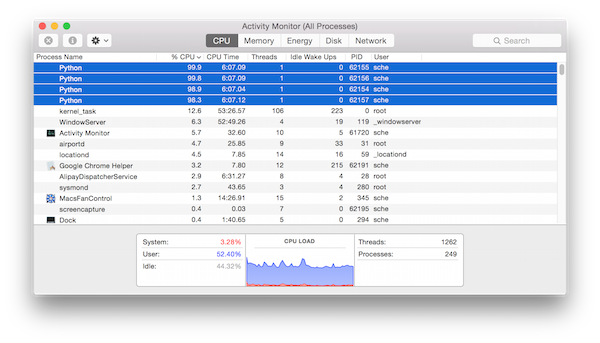
当然有这个玩意儿还不够,虽然把CPU占用率提上去了,但是MAC的风扇会狂转,这样可会觉得比较吵。下载个Macs Fan Control,将风扇的控制策略改为固定最低,这样就好了。
如果嫌火力不够大,将上面的cpus改为更大的值即可,但是这样会让系统反应很慢哟。
TIPS:现代的CPU当温度过高的时候会自动的降低频率,所以在高温时运算速度会下降的。
冬天好冷,加上mac的金属外壳,更冷。写个暖宝宝给MAC吧,好歹手会不会再冷了。
import multiprocessing |
当然有这个玩意儿还不够,虽然把CPU占用率提上去了,但是MAC的风扇会狂转,这样可会觉得比较吵。下载个Macs Fan Control,将风扇的控制策略改为固定最低,这样就好了。
如果嫌火力不够大,将上面的cpus改为更大的值即可,但是这样会让系统反应很慢哟。
TIPS:现代的CPU当温度过高的时候会自动的降低频率,所以在高温时运算速度会下降的。
基于对数据的兴趣以及对技术的渴望,在大数据这个年代,没有数据怎么空谈大数据。数据的获取方式多种多样,可以下载,可以从政府的网站上免费获取,有钱的话可以从别人那里买到,或者自己动手做爬虫爬数据。
从2011年开始,那时候还在华为的时候,每年过年要回广州家,每次买机票都会观察一段时间然后下手。自己想搞清楚一个问题:提前多少天,在什么时候我能最高概率的买到最便宜的机票?然后就开始研究起来了淘宝、去哪儿、酷讯的页面如何爬,积累了很多经验,同时这些经验又会给我们的网站设计提供反向的思考。当然我这里所要讲到的我的爬虫,并不是广义上的百度、谷歌的爬虫,而是对特性数据的深度爬虫。这种爬虫所用到的技术面更窄,针对性更强,面临的挑战也不一样。
作为爬虫和网站,两个对立的群体,会面临很多的问题。网站作为服务的提供者,一来想保护自己的业务不会受到非法的攻击,会采取各种措施来防止非法的数据获取,另一方面对于普通的用户又不想将用户体验搞得很糟糕。爬虫的目的就是为了数据,会想尽一切的办法来获取,尽量的获取更多的数据。攻防之战总会升级,每每解决一个特别棘手的问题后,都会为自己的技术而感到沾沾自喜,也会期待网站的再次升级。
下面是去年的时候整理的一个图,我会在后续的博客里面进行深度的分析。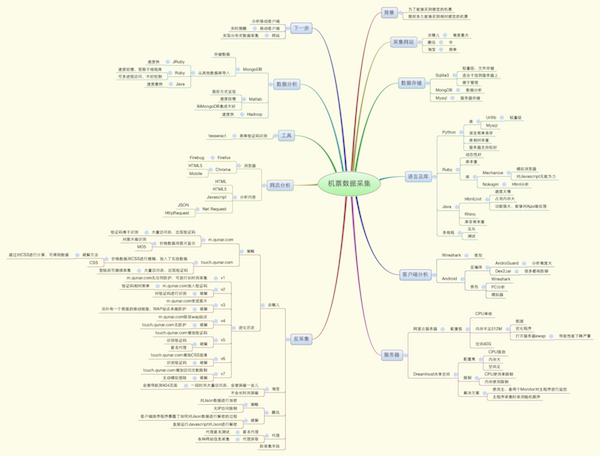
每隔一段时间,都会重新搞一下博客。博客系统也换过多次,Wordpress->Ghost->Jekyll->Wordpress。Ghost虽然说得很好,但是还很不成熟,插件、主题都很缺乏。静态生成的Jekyll速度慢的很,完全无法折腾几百篇的博客。最终回到古老笨重的Wordpress。
还好朋友给我说了个hexo,基于nodejs,试用了一下速度很快,插件也比较完善,结合github pages我就不担心DigitalOcean上的VPS性能问题了,可以腾出来做点别的事情。
首先将Wordpress的文章全部导出到xml,然后用exitwp将博客转成markdown。期间修正许多xml中的错误,折腾了好久。转换后的markdown也不完全的对,需要人工进行一些编辑,以前所见即所得的编辑器搞
得格式一塌糊涂,转换成markdown以后花了两天时间将所有的博文清理了一次,才算大部分完成。
有些代码的格式损坏了,后续可能还得写个插件,将code block中的代码自动格式化一次。
至于图片,以前博客的很多图片丢失了。曾经在用Wordpress的时候喜欢用一些相册插件,然后在文章中直接插入一些标记。当然这些插件真的很费事,万一重装了Wordpress或者数据库损坏了,以前的关联也损坏了。回头我会在之前的一些备份的压缩包里面看看是否还能找到以前的图片,或许还能找回一些好玩的东西。
2012年底,当时还在华为的时候,新的项目面临非常大的时间压力,要求在一个月之内搞定最初的代码,包括编译、链接。状况是成都、武汉、深圳三地几十个开发人员共同合上上十万的代码,而代码管理软件用的是ClearCase(如果你不知道,那么看看吧)!
ClearCase用的是悲观锁机制,一个人锁了文件别人无法取出来;没有原子commit,意思是每个文件只能单独提交,无法跟踪同样的修改,甚至你能只能提交.h而.cpp被人锁了没法提交,大家自然也无法编译;分布式的环境造成ClearCase异常的慢,大家都在做徒劳的加班,经常有人大骂别个又锁了文件还没释放,经常我的提交被别人干掉,我得重来。
我乐观的预计,照这个速度,7*24的话3个月都搞不定。那我们来试试别的方式吧。
我大胆的给PL、PM建议,用git吧。领导说git大家不会,会不会很麻烦,我们还是用SVN吧,大家都用过,公司也有服务器啥的。其实大家最多就听过SVN,对于git这玩意儿鲜有人知。而我之前已经在本地一直用git很长时间,并结合git-svn管理代码了。
对于这种分布式、大量的merge和慢速的网络的情况下,git的分布式、自动merge、增量式提交直接解决这些要害问题。当然对于新鲜的事物,大家都很谨慎,而且对于华为这样的企业,对于源代码之内的东西都是非常重要的。当然,要推动大家,必须要让大家会用,并且要非常简单。Project Leader决定让我冒个险。
还好TortoiseGit和TortoiseSVN都差不多,有些开发人员用过TortoiseSVN管理过文档,所以还是有一定的基础。我花了数个小时搭了一个http git服务器,当然用的是最简单的。然后花了1个小时时间给几十个人讲这个怎么用。当然原理只能一概而过,十多分钟吧。然后重点是实践,那么怎么样最简单?我总结了几个步骤:* 本地修改
别去理会其他的东西,坚持这几个步骤绝不会出错,我们都在一个master上工作。我建了一个临时的仓库,大家试了一把,果然好用。规则简单、速度快、大部分情况不用手工解决冲突。
就这样,三个团队一个月轰轰烈烈的完成了所有的任务,而且质量好。由于这个合上去的版本只能作为临时的选择,所有的代码最终合入到了SVN中,彻底消灭了ClearCase。当然这期间版本软件转换还是很费力,申请权限、申请空间、教会大家怎么用。
最近遇到的pull –rebase的问题就是个麻烦事。项目组之前约定说merge的commit太难看了,用pull –rebase能够解决问题。试了试,果然好用。直到突然用了分支以后,出现了奇葩的问题。
创建一个分支,然后做一些修改,例如C1,C2。然后merge到master上,创建一个C3,这时候再master分支上pull –rebase,瞬间就傻了。你会发现C3不见了,C. C2在master上重建为C1’,C2’,有时候如果当初merge的时候有冲突,这时候你还得来一遍。最后,你的分支就变成了一个unmerged分支,而且永远没法合回去了。
第一次遇到这个坑以后,我以为是自己的问题;第二次遇到后,决定研究一下。这里有一些资料:
http://stackoverflow.com/questions/6248231/git-rebase-after-previous-git-merge
https://sethrobertson.github.io/GitBestPractices/
其实rebase的优点主要是没有auto merge的那个commit,带来的副作用远比这个洁癖多(https://sethrobertson.github.io/GitBestPractices/):
A specific circumstance in which you should avoid using git pull –rebase is if you merged since your last push. You might want to git fetch; git rebase -p @{u} (and check to make sure the merge was recreated properly) or do a normal merge in that circumstance.
Another specific circumstance is if you are pulling from a non-authoritative repository which is not fully up to date with respect to your authoritative upstream. A rebase in this circumstance could cause the published history to be rewritten, which would be bad.
Some people argue against this because the non-final commits may lose whatever testing those non-final commits might have had since the deltas would be applied to a new base. This in turn might make git-bisect’s job harder since some commits might refer to broken trees, but really this is only relevant to people who want to hide the sausage making. Of course to really hide the sausage making you should still rebase and then test each intermediate commit to ensure it compiles and passes your regression tests (you do have regression tests, don’t you?) so that a future bisector will have some strong hope that the commit will be usable. After all, that future bisector might be you.
Other people argue against this (especially in highly decentralized environments) because doing a merge explicitly records who performed the merge, which provides someone to blame for inadequate testing if two histories were not combined properly (as opposed to the hidden history with implicit blame of rebase).
Still others argue that you are unable to automatically discover when someone else has rewritten public history if you use git pull –rebasenormally, so someone might have hidden something malicious in an older (presumably already reviewed) commit. If this is of concern, you can still use rebase, but you would have to git fetch first and look for “forced update” in that output or in the reflog for the remote branches.
You can make this the default with the “branch.
.rebase” configuration option (and more practically, by the “branch.autosetuprebase” configuration option). See man git-config.
虽然这里给出了解决问题的办法,但实在是太麻烦了。如果你容忍不了这个auto merge,那你得冒着搞坏别人或者搞垮自己的风险。当然如果你说我就喜欢折腾,我是git大牛,我就喜欢这么折腾。那我也没办法。
回过头来,如果考虑到整个团队的水平、学习曲线及平时的管理难度,我认为还是先暂时用着最原始的auto merge吧,虽然有几个难看的commit。
Updated 2015.3.12
对于这个问题,按照git的习惯当feature分支被合并进master以后,以为你的工作已经完成,所以这个分支也就必须要删除了。然后如果后需要新增一些工作或者修改,则需要重新啦分支。这样就可以避免这样的问题了。
总之,我们用工具是为了生活更美好。如果这个事情把问题搞的越来越复杂复杂,或者为了炫耀自己熟知这个命令的n多个坑,而你不知道,我认为这和回字的三种写法(回、囘、囬)是一样的道理。
一般来讲,从哲学上说,简单的东西一般是对的(http://en.wikipedia.org/wiki/Occam’s_razor)。最后,分享一个Atlassian Blogs上的一篇博客(http://blogs.atlassian.com/2013/10/git-team-workflows-merge-or-rebase/)作为结尾吧。没时间看的,你可以只看Decisions, decisions, decisions: What do you value most部分。
2011年3月份还在华为夜以继日的时候,买过一本《领域驱动设计:软件核心复杂性应对之道》,虽然努力的看过一次,没看懂,觉得都距离我很遥远。2014年4月,在ThoughtWorks还不到一年,买了一本腾老板的《实现领域驱动设计》,看了一遍,似乎理解了一些,但还是有些摸不着头脑。


做IT的一方面白天要鼓足干劲干好那8小时,回家每天抽时间陪小孩玩耍一两个小时,另一方面又要在9点半之后尽快的吸取最新的营养,实乃不容易。回想起老婆回娘家的那段时间已经自己出差的一个月,真是非常难得,可以抓紧时间读书、试验新的技术。ThougtWorks的读书文化我很欣赏,别个同事每年读个50本书,我却用Training Budget买了很多书回来,就放在那里了。这并不是说我费钱,主要是中国的出版业很奇葩,你不买可能过段时间就成绝版了,想买也买不到了。我每过一段时间就要清理了一下,感叹一下书非借不能读也,真想静下心来重新读书。
读书,别开电脑,离开你的手机,摒弃一切的,拿上一支记号笔,开始吧。
重新读《领域驱动设计:软件核心复杂性应对之道》正是由于做到了项目的后期,觉得整个项目已经开始凌乱。大家对业务知识不了解,也没问,只求赶紧将东西搞出来;对技术只见树木不见森林,虽然有很精巧的重构,但无法反映出真实的业务场景;有多个的Micro Service但有些职责显得混乱不堪。团队在一个混沌的情况下越来越晕,我真是想找个时间重新审视一下这个系统,如何在新的一年有更好的发展?
对于一个良好的系统而言,还是需要一个靠谱的模型。然而团队并没有给出这个模型,最早的时候都是按照View Model来建模,映射Field,然后对其进行处理。再引入了Micro Service后,情况有所转变,因为Share的原因必须要让开发者思考Domain Model,然后对页面进行去耦合。这是一个好事情,但尚处于一个模糊的阶段。
领域模型也迫使开发人员学习重要的业务原理,而不是机械的进行功能的开发。
这正是我们目前开发人员很缺的一块儿。作为一个常见敏捷开发团队,一般配置BA(业务分析人员)、DEV(开发人员)、QA(测试人员)。BA和业务人员谈论需求,并且分解为Story卡,DEV可能会参与其中的技术讨论,但对业务知识也只是一知半解,甚至都没有对业务知识的追求。短时间内,这个也没有太大的问题,BA充当了业务人员和开发人员之间的一个翻译,但往往业务人员和开发人员之间存在了语言的障碍。
在之前的项目中,我也仅仅只作为DEV来实现一些需求。对于背后的业务逻辑,BA告诉我即可,别多想了。长此以往,DEV最后就真正的变成了Coding Monkey,而现实的情况是Coding Monkey越来越便宜。所以开发人员必须要逐渐的懂业务,从业务上思考问题,才能跳出Coding的圈子。

好在我们项目,由于BA的能力欠佳,我们不得不跳出常见的开发团队,让多个经验丰富的开发人员尝试更多的时间跳过BA直接和业务人员打交道。一来是意思传达的更准确,二来是增进了开发人员和业务人员的交流。虽然这样通常会让开发人员多出20%-30%的时间用于更多的沟通,对于开发的效率有所影响,但总体而言物有所值。甚至Iteration Manager Fabio(我只能说和这样的牛人一起工作实乃幸运)也鼓励开发人员这么做。我想如果今年团队能够突破英语的障碍,直接和业务人员沟通,BA这个职位都可以淡淡的弱化了,人人当BA。当然还得感谢ThoughtWorks能够有比较小的敏捷的团队。否则类似于华为、中兴这样的大企业,开发人员几乎没有和业务人员沟通的机会,造成做了半天都不知道具体的业务场景是啥,写出来的代码难免会错误百出。
Ubiquitous Language,通用语言。
这种语言可以用于团队的沟通,也可以用于描述软件本身。于领域专家谈话的时候也需要使用这种语言,能够消除彼此之间的隔阂,让开发人员更容易的理解业务。而开发人员也应该使用这种语言来阐述需求,消除模糊的语言。
然而我们没有,甚至各种名词彼此混淆冲突。举一个现实的例子是ANZSIC和Occupation。ANZSIC是指_The Australian and New Zealand Standard Industrial Classification_,而Occupation是指在某业务部分对ANZSIC的细分用于更精确的定价及投保。
我刚到项目组的时候,就发现代码中混淆着ANZSIC和Occupation这样的类、字段和变量,问了两三个人也没解释清楚,大家的理解这两个东西好像是一回事。后续和业务人员沟通的时候,我们也会将ANZSIC说成Occupation,造成很多的混乱。甚至在做设计的时候,也会混用这两个词。我快要晕了。
我决定停止这样的混乱,找业务人员问清楚。原来ANZSIC和Occupation比较类似,ANZSIC是4位编码(例如3232)。而Occupation是对应的ANZSIC的扩展,例如3232对应的ANZSIC还不足以区分投保,所以Occupation再3232的基础上再加2到4位,变成323201或者32320101。这样就解决了ANZSIC细分粒度的问题。
搞清楚这个事情以后,写到了一个Terms的文档中,并且在整个团队及相关的团队中都共享这个知识,每次有人错误提及的时候我都会纠正一遍。这样好歹基本上大家都搞清楚了。但这个混乱的成本也很大。代码中的混乱,已很难改变。很多JSON对象中也是乱套的用,多个Micro Service的API也不好改,甚至有些本该是ANZSIC的写成了Occupation,对类的重命名会造成类定义的混乱。这是个鲜活的例子,开发人员应该搞清楚每个名词的真正含义并不断修正之。
新加入团队的成员很是不理解为什么代码里面几乎没有什么注释。作为一个自解释的代码,保持代码短小,命名清晰,可以保证大部分时候不需要什么注释。但千万别走极端,代码无法解释的内容,例如一些比较难理解的设计用途,或者一些不通常的实现方法,都需要有一些注释作解释。
那么设计文档呢?可能有时候开发人员过于自信自己的水平,认为可执行的测试就表明了一切,就不需要文档。但他们可能没有遵循TDD,造成测试遗漏;或者没有能力管理好成千上万的测试;或者测试命名、意图描述的不准确。这些因素都可能造成一些歧义。让一个新来的人员直接看这些测试,直接就会晕死在各种细节中。
仅仅使用代码这一种文档形式与过度地使用UML图具有同样的基本问题。文档不应该重复表示代码已经明确表达出的内容。
我们项目每个开发人员会负责一个特性,在每个迭代的分析阶段会有一些文档性的东西支撑。但我基本不会将代码中实现的东西在文档中又说一遍,例如类图这种东西,一旦我重命名就完全不一致了。甚至API的设计,我只会说基本原则,并参考API测试,那里有你所需要的。最后,我会讲解整个特性的基本实现原理及一些约束,这种代码之外的补充文档才是充分有用的。